FAQs
Welcome to our compilation of the most Frequently Asked Questions we have received so far.
We will continue expanding this page and adding sections with resources, so stay tuned!
Feel free to reach out to our email or social media accounts (links at the top of the page) if you have additional questions or suggestions!

Your questions answered
What is DAPR?
DAPR is short for Data Science and Analytics for Precision Rehabilitation.
The goal of the DAPR Center is to generate large, harmonized rehabilitation datasets that will enable artificial intelligence (AI) and machine learning (ML) methods for precision rehabilitation and improve the rigor of medical rehabilitation research.
In a nutshell, DAPR aims to prepare rehabilitation data for AI and ML analyses by creating a user-friendly data-sharing ecosystem that includes tools, training, and resources.
What does the DAPR ecosystem look like?
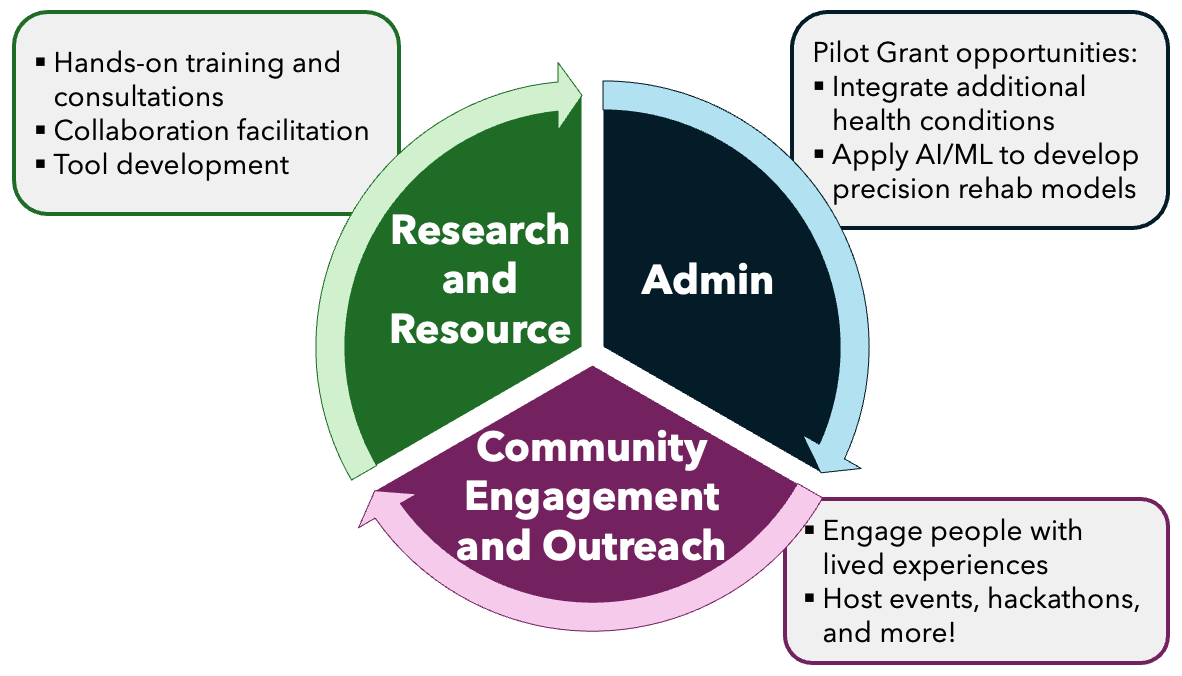
We divided all tasks mainly into 3 main cross-functional Cores: Research and Resources, Administrative, and Community Engagement and Outreach; each dedicated to specific tasks of the DAPR ecosystem, outlined in the figure below.
Wait, is there a backstory for DAPR?
Yes! All this builds on the efforts and lessons learned from aggregating neuroimaging data from stroke research (see the ENIGMA Stroke Recovery Working Group) and teaching data science principles to rehabilitation researchers and clinicians (see the ReproRehab Education Program).


We are also one of six NIH-funded national centers working on solving related problems, and we have strong collaborations with all of them!
Who are the other centers?
The Medical Rehabilitation Research Resource Center (MRRRC), funded by the NIH P50 Mechanism to "Advance Team Science through Thematic Centers". These centers are:
Center for Advancing Precision Neural Circuit-Based Rehabilitation (Neuro-PRECISE)
National Center for Foundational Artificial Intelligence for Rehabilitation (FAIR) Center
Data Science and Analytics for Precision Rehabilitation (DAPR) Center
ENGAGED: Disability Community Engaged Medical Rehabilitation Research Center
Let's go back to the data.
What is the challenge that DAPR aims to address?
AI and ML require large datasets to make accurate predictions. However, rehabilitation data have been typically acquired in small sets across many research groups. Therefore, one way to leverage past and current efforts in rehabilitation research is to aggregate data that different groups have already collected.
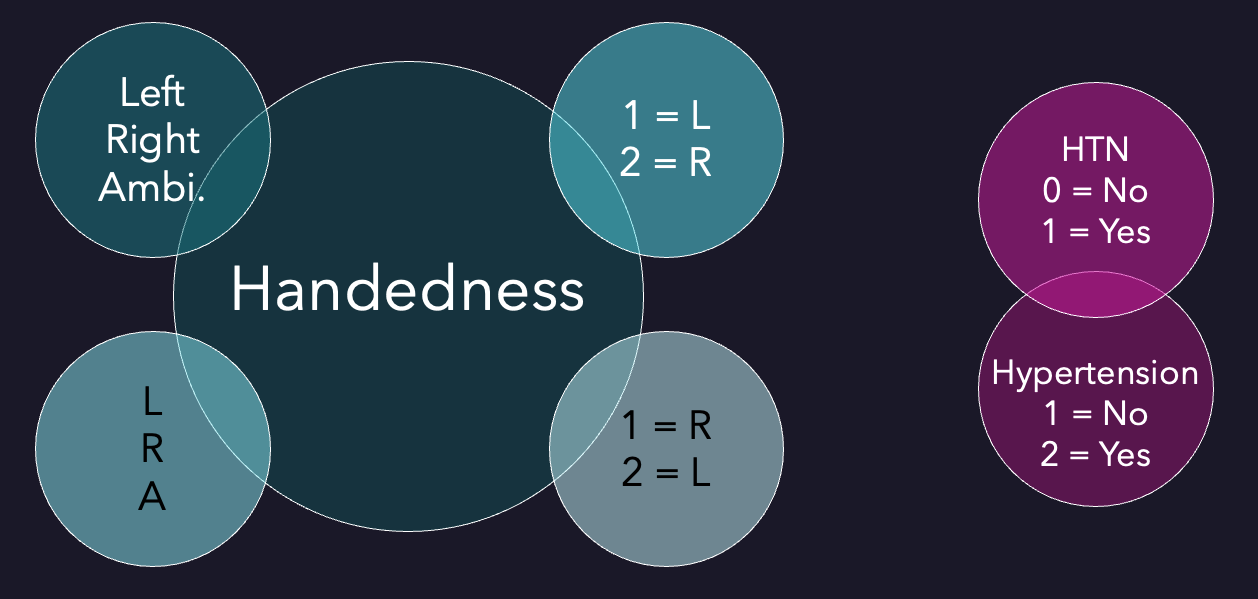
However, this presents an additional challenge, as research groups might use different conventions and standards to collect and store otherwise similar data. For example, one laboratory might record its research participants' weight in pounds and another in kilograms, or encode people's handedness as Left/Right/Ambidextrous, L/R/A, or 1/2/3 (where 1 could mean Left in one dataset and Right in another), or refer to the same information with different names (e.g., HTN and Hypertension).
Therefore, the first step to aggregate this highly heterogeneous data is to harmonize it. In other words, ensure all variable names and their associated values and codes represent the same information. Traditionally, this has been done via manual verification processes. However, as we increase dataset sizes by adding more observations from more sources, the task becomes exponentially more challenging and time-consuming.
Are you the first ones working on something like this?
It is important to note that similar efforts have aimed to standardize healthcare data across institutions. For example, with the development of Common Data Models (CDM), like the Observational Medical Outcomes Partnership Common Data Model (OMOP) and the National Institute of Neurological Disorders and Stroke Common Data Elements (NINDS CDE).
However, as these were primarily developed to address the needs of healthcare providers, their rehabilitation-related variables often lack the granularity and detail found in rehabilitation studies and interventions (e.g., itemized behavioral assessments). Thus, the rehabilitation community could benefit from a model that targets its specific needs. That said, we aim to integrate these existing models into our own to facilitate their inclusion into rehabilitation research.
Okay, so what are you doing to address all this?
Two of the first goals of DAPR are to develop:
A human-readable and machine-readable data schema specifically designed for rehabilitation data that
Captures the extent and granularity required in rehabilitation studies and interventions.
Is modular and scalable to incorporate multiple health conditions (e.g., stroke, Parkinson's Disease, Cerebral Palsy) and environments (e.g., laboratory, clinical, real-world).
A user-friendly application to map existing datasets to the DAPR Schema and other established CDMs.
We are calling these the DAPR Schema (the structure for organizing and building our dictionary), DAPR Dictionary (a curated collection of rehabilitation-relevant variables), DAPR Thesaurus (a cross-reference map between some existing CDMs), and DAPR MAPR (our mapping application).
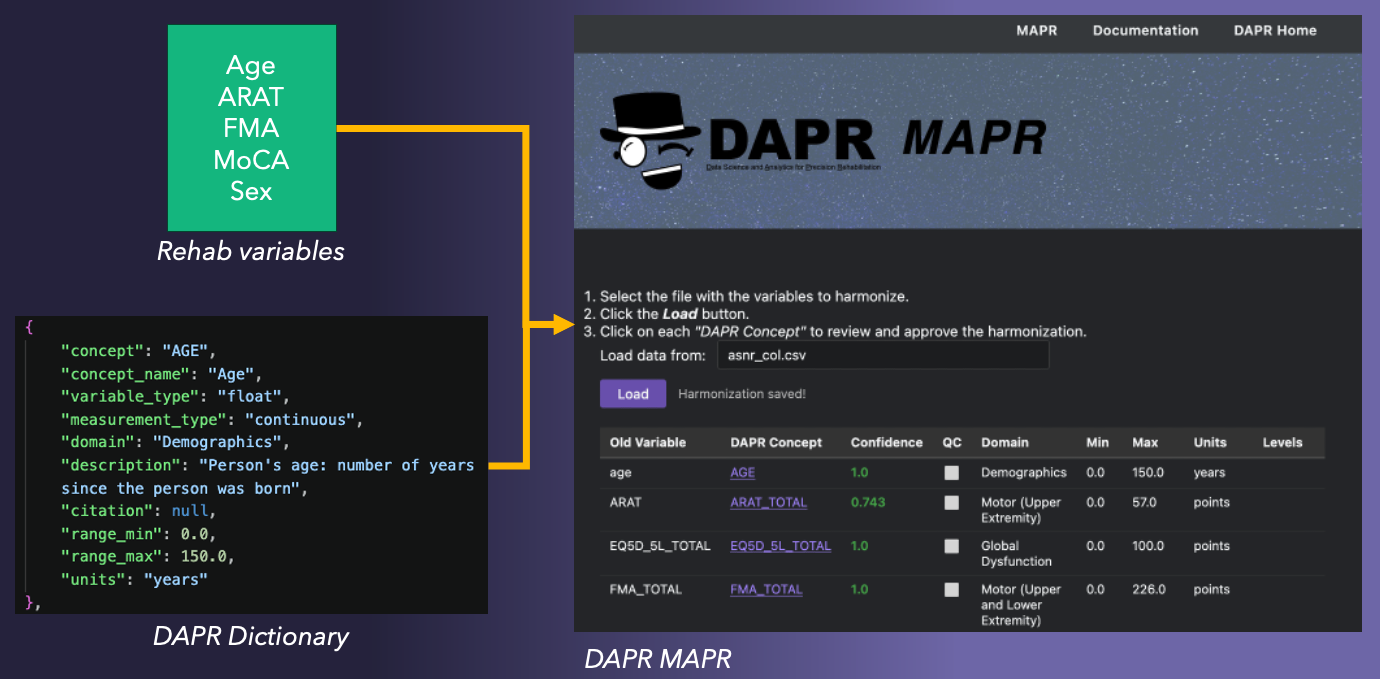
What is DAPR MAPR?
Short for Mapping Application to Prepare Rehabilitation data, MAPR is an interactive web application to help researchers harmonize their data.
On its first release, DAPR MAPR will use AI to take the variable names the researcher used, find corresponding best matches within the DAPR schema, and provide a suggested data dictionary (with an accuracy probability) to map the original names to DAPR names and associated CDEs in the OMOP CDM.
Will MAPR use my data to harmonize it?
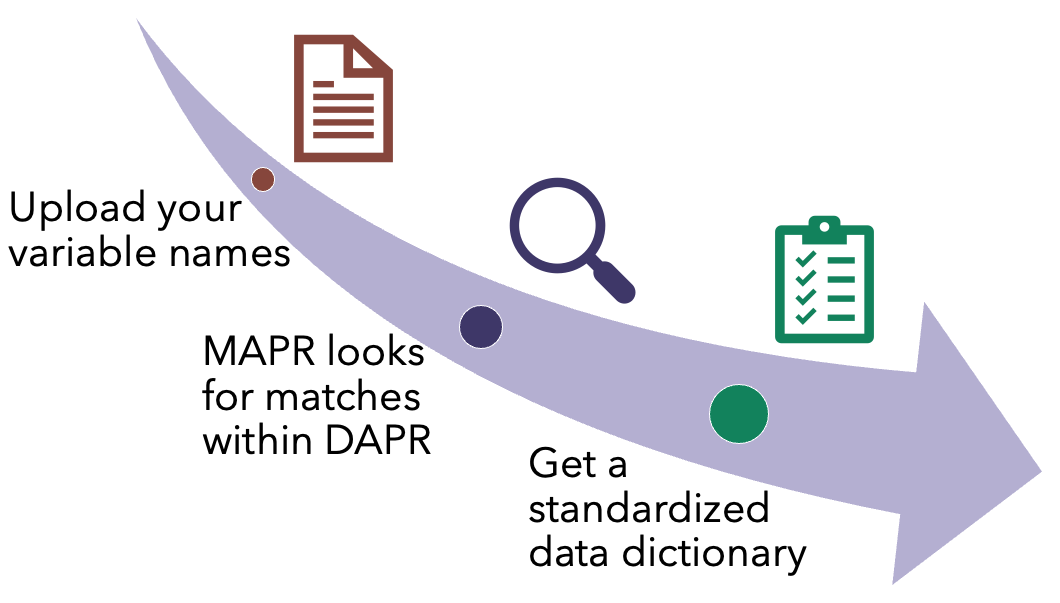
Not yet. MAPR does not need access to the complete dataset. In this first iteration, it will just take the variable names (from a CSV file) to provide suggestions of standardized names and a dictionary key (also saved as a CSV). This will help you prepare your data to share it with other researchers or combine it with similar datasets.
However, we are concurrently working on the next release, which will have the ability to take a sample of the data to implement more robust mappings and assist with the data validation process.
Below is a quick demonstration of the current version of DAPR MAPR.
Exciting!
What comes next?
In terms of development, among the next steps in our efforts to create AI/ML-ready rehabilitation datasets are:
Incorporate into the DAPR dictionary variables from other medical conditions like Parkinson's Disease and Cerebral Palsy
Incorporate into the DAPR Thesaurus concepts from the NINDS CDEs
Set up infrastructure to organize and store time-series data (e.g., form gait studies)
Set up infrastructure for federated learning approaches.
In the meantime, we are working to launch a Pilot Grant application for researchers to start using the tools we have developed so far. So stay tuned!
Be sure to subscribe to our newsletter and follow us on social media (@daprdata, links at the top of the page) to be among the first to know about our progress, events, and releases!
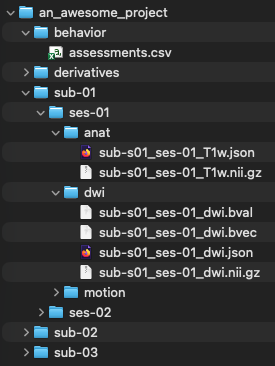
What can I do now to prepare?
Right now, keeping your data in any machine-readable format will be a huge help. For example:
Having consistent folder structures (e.g., each subject folder has within it folders for raw_data, processed_data, etc.)
Using a consistent naming convention (e.g., subj01, subj02, subj03)
Storing associated data and metadata in CSV, TSV, JSON, or text files
A good place to start could be following one of the standards that the neuroimgaing community has widely adopted: the Brain Imaging Data Structure (BIDS), which organizes data and metadata on a hierarchical level.